# COMPUTE 1. [Processes](#1-processes) 1. [Threads](#2-threads) 1. [Scheduling](#3-scheduling) 1. [Synchronization](#4-synchronization) --- ## Backstory --- ### Backstory Software running while you are doing your homework: * Code editor * Browser with 10+ <https://stackoverflow.com/> tabs * Discord * Spotify * Bittorrent client * Crypto miner * The OS itself Only one CPU. How? ---- #### Some CPU internals 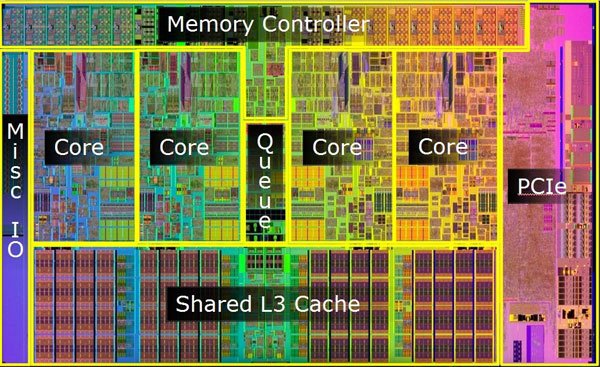 * Multiple **cores** per CPU * Still not enough for all processes ---- #### All Processes in a System ```console student@os:~$ ps -e | wc -l 32 student@os:~$ ps -e PID TTY TIME CMD 1 ? 00:00:00 init 914 ? 00:00:00 init 2582 ? 00:00:07 gpg-agent 19812 ? 00:00:00 init 19813 ? 00:00:00 init 19814 pts/0 00:00:00 bash 20650 ? 00:00:00 init 20651 ? 00:00:00 init 20652 pts/1 00:00:00 sh 20653 pts/1 00:00:00 sh 20658 pts/1 00:00:00 sh 20661 pts/1 00:00:03 node 20672 ? 00:00:00 init 20673 ? 00:00:00 init 20674 pts/2 00:00:00 node 20681 pts/1 00:00:00 node 20701 ? 00:00:00 init 20702 ? 00:00:00 init 20703 pts/3 00:00:01 node 20722 pts/1 00:00:00 node 20733 pts/1 00:00:18 node 20796 pts/1 00:00:25 node 20915 ? 00:00:00 init 20916 ? 00:00:00 init 20917 pts/4 00:00:00 bash 20964 pts/4 00:00:00 python3 20981 ? 00:00:00 init 20982 ? 00:00:00 init 20983 pts/5 00:00:00 bash 21045 pts/5 00:00:00 ps ``` Way more processes than cores! --- ## Processes --- ### Processes * A process is a **running program** * It is a collection of resources (Memory, CPU, I/O) and abstractions over them (VAS, threads, file descriptors) * An application can spawn multiple processes * The OS allows each [thread](./threads.md) to run on a **core** for a few milliseconds (time slice) * Then the OS pauses the thread and replaces it with another one (context switch) ---- #### What We Want * Run more apps than cores * Use resources efficiently: * Memory: isolated data * CPU: low idle times * I/O: responsiveness ---- #### Resource Management - Overview  ---- #### What We Don't Want * Unresponsive processes * Processes monopolizing resources * System freezes --- ### Process Address Space * Each process has its own **Virtual Address Space (VAS)**: * Isolation * The process "thinks" it uses the entire address space ---- #### Process Virtual Address Space  --- ### Process Attributes - from User Space * PID: numeric identifier * PPID: parent's PID (one parent per process) * running time * threads ```console student@os:~/.../compute/lecture/demo/create-process$ python3 create_process.py [parent] PID = 186411 [parent] Before starting, child PID = None [parent] After starting, child PID = 186412 [child] PID = 186412; PPID = 186411 [child] Message from parent: OS Rullz! ``` --- ## Threads --- ### Threads - Backstory * You have an application that applies filters to a set of images * If we used processes to spread the work: * images (like all data) would be marked copy-on-write * processes cannot easily modify the "shared" images * **Solution:** use threads * No copy-on-write: threads share the heap and data sections ---- #### Threads - Definitions * Scheduling unit * Lightweight processes (LWP) * Each process has at least one thread --- ### App, Process, Thread - The Bigger Picture * [Quiz](../quiz/threads-shared-data.md)  --- ### Process vs Thread | PROCESS | THREAD | | :------------------------------- | :----------------------------------- | | independent | part of a process | | isolated VAS | shares VAS with other threads | | slower creation | faster creation | | larger context switch duration | shorter context switch duration | | ending means ending all threads | other threads continue when finished | ---- #### Process vs Thread `demo/create-thread/create_thread.py` vs `demo/create-process/create_process.py` --- ### Process Attributes --- #### Process Attributes - from User Space ```console student@os:~$ ps -e --forest -o pid,ppid,rss,vsz,etime,stat,comm PID PPID RSS VSZ ELAPSED STAT COMMAND 1 0 600 988 2-02:44:02 Sl init 914 1 88 900 2-02:14:06 S init 2582 914 3376 82956 1-04:15:56 Ss \_ gpg-agent 19812 1 176 988 09:03:34 Ss init 19813 19812 176 988 09:03:34 S \_ init 19814 19813 6420 11256 09:03:34 Ss \_ bash 21713 19814 3132 10696 00:00 R+ \_ ps 20650 1 176 988 05:43:41 Ss init 20651 20650 176 988 05:43:41 S \_ init 20652 20651 604 2612 05:43:41 Ss+ \_ sh 20653 20652 536 2612 05:43:41 S+ \_ sh 20658 20653 604 2612 05:43:41 S+ \_ sh 20661 20658 74072 931768 05:43:41 Sl+ \_ node 20681 20661 44316 614424 05:43:40 Sl+ \_ node 20722 20661 39804 828152 05:43:40 Sl+ \_ node 20733 20661 147004 845832 05:43:40 Sl+ \_ node 20796 20733 119336 959952 05:43:38 Sl+ \_ node 21149 20733 41080 581504 04:31:20 Sl+ \_ node 20672 1 176 988 05:43:40 Ss init 20673 20672 176 988 05:43:40 S \_ init 20674 20673 41556 585172 05:43:40 Ssl+ \_ node 20701 1 176 988 05:43:40 Ss init 20702 20701 176 988 05:43:40 S \_ init 20703 20702 48060 590308 05:43:40 Ssl+ \_ node 20915 1 176 988 05:24:46 Ss init 20916 20915 176 988 05:24:46 S \_ init 20917 20916 5268 10188 05:24:46 Ss \_ bash 20964 20917 19840 516296 05:24:32 S+ \_ python3 20981 1 176 988 05:22:54 Ss init 20982 20981 176 988 05:22:54 S \_ init 20983 20982 5100 10056 05:22:54 Ss+ \_ bash ``` ---- #### Process Attributes - from Kernel Space * Process Control Block (PCB): * Data structure in the kernel * [`task_struct`](https://elixir.bootlin.com/linux/v5.19.6/source/include/linux/sched.h#L726) in Linux * [`EPROCESS`](https://www.nirsoft.net/kernel_struct/vista/KPROCESS.html) in Windows * [`proc`](https://github.com/apple/darwin-xnu/blob/main/bsd/sys/proc_internal.h#L182) on XNU, the Apple iOS / macOS kernel * All information about the process (from `ps`, `/proc`) * Threads use a **Thread Control Block (TCB)** * the [execution context](https://linux.die.net/man/2/setcontext) is a **thread** ---- #### Process Attributes - from Kernel Space The most important fields in `task_struct`: ```c [2 | 4 | 6 | 8 - 9 | 11 - 13 | 15 - 16 | 18 - 19 | 21 | 23 | 25 - 26 | 28 - 29] struct task_struct { unsigned int __state; void *stack; unsigned int flags; int on_cpu; int prio; /* Scheduler information */ struct sched_entity se; const struct sched_class *sched_class; /* The VAS: memory mappings */ struct mm_struct *mm; int exit_state; int exit_code; pid_t pid; struct task_struct __rcu *parent; /* Child processes */ struct list_head children; /* Open file information */ struct files_struct *files; }; ``` --- ## `fork()` --- ### `fork()` * Spawns child process * Child process starts execution right after the call to `fork()` * Returns twice * `0` in child process * Child's PID in parent process * [Quiz](../quiz/process-creation.md) * Initially child and parent share the same PAS (Physical Address Space) * Child's writable pages are marked **copy-on-write** ---- #### `fork` and Threads * `fork` also creates a new thread... * ... but part of a different process  --- ## Copy-on-write --- ### Copy-on-write When `fork` returns, the child duplicates the contents of the parent's page table.  ---- #### Copy-on-write * Writable pages are **copied and modified only** when written: `demo/copy-on-write/copy_on_write_overhead.c` * [Quiz](../quiz/sections-always-shared.md)  ---- #### Copy-on-write Overheard * Writes cause minor page faults ```console student@os:~/.../compute/lecture/demo/copy-on-write$ ./copy_on_write_overhead * Child process started -- Press ENTER to continue ... Time for reading 131072 pages: 30 ms * Child process read pages -- Press ENTER to continue ... Time for writing to 131072 pages: 222 ms [...] ``` * The child process performs exactly 131072 **minor** page faults when writing data ```console student@os:~$ cat /proc/`pidof copy_on_write_overhead`/stat | cut -d ' ' -f 10 # before writing 22 student@os:~$ cat /proc/`pidof copy_on_write_overhead`/stat | cut -d ' ' -f 10 # after writing 131094 ``` --- ## Scheduling --- ### Scheduling - Why? * For multitasking: more threads than CPU cores * For responsiveness: small waiting time * For productivity: execute more threads ---- #### Typical Thread Execution  ---- #### Thread States * At most one RUNNING thread per core * Queues for BLOCKED and READY threads * [Quiz](../quiz/number-of-running-threads.md) <img src="media/thread-states.svg" alt="Thread State Diagram" style="width:700px;"/> A more detailed diagram is [here](./cool-extra-stuff.md#the-suspended-states) --- ### Context Switch - When? * Voluntary - initiated by the running thread: * RUNNING thread performs a blocking action (eg: I/O call) * The thread calls `yield()` / `SwitchToThread()` * Involuntary - initiated by the OS: * RUNNING thread ends * RUNNING thread's time slice expires * A thread with higher priority is READY ---- #### Context Switch - How?  --- ### Types of Threads * CPU-intensive / CPU-bound = mostly CPU bursts: * compute the digits of Pi * compilers * machine learning * I/O-intensive / I/O-bound = mostly I/O bursts: * servers * databases * text editors ---- #### IO-bound vs CPU-bound * `demo/context-switch/cpu_bound.c`: ```[1 - 4] student@os:~$ cat /proc/$(pidof cpu_bound)/status [...] voluntary_ctxt_switches: 13 nonvoluntary_ctxt_switches: 7 ``` ---- #### IO-bound vs CPU-bound * `demo/context-switch/io_bound.c`: ```console student@os:~$ cat /proc/$(pidof io_bound)/status [...] voluntary_ctxt_switches: 3729 nonvoluntary_ctxt_switches: 3 ``` --- ### Context Switch - Overhead * Causes of overhead: * running the scheduler itself * flushing the [TLB](../../data/lecture) of the evicted thread is required * the new thread starts with an empty TLB * Faster context switches between threads of the same process because their TLB is not flushed --- ## Scheduling Algorithms --- ### Scheduling - Ideals * **Interactivity:** decrease time spent in READY * low waiting time * also known as **fairness** * **Throughput:** finish threads as quickly as possible * low turnaround time ---- #### Scheduling - Reality * There is no free lunch * Trade-off between interactivity and throughput ---- #### Types of Schedulers * **Cooperative:** only allow voluntary context switches * Advantage: Simple to implement * Disadvantage: starvation - a thread might never yield its CPU core * **Preemptive:** also allows involuntary context switches * Each process can run at most a certain _time slice_ * When it expires, a context switch is triggered ---- #### Scheduling Algorithms - The Bigger Picture * **Round-Robin**: * Push each new thread to a queue * Every time slice, dequeue one thread, run it, then reenqueue it * Threads run in the order in which they're spawned ---- #### Scheduling Algorithms - The Bigger Picture * **Completely Fair Scheduler (CFS)**: * Add new threads to a red-black tree sorted by total running time * Every time slice, remove, run and add the thread that has run the least back to the tree * Each thread runs approximately the same amount of time --- ### Scheduling Algorithms - Round-Robin 1. Add each new thread to a queue 1. Remove one thread from the queue and run it 1. The thread runs until finished or until its time slice ends 1. If the thread is not finished, add it back to the queue 1. Repeat from step 2 ---- #### Round-Robin - Example | Process | Running time | | :-----: | :----------: | | P1 | 4 | | P2 | 3 | | P3 | 5 | * Assume a time slice of 2 ---- #### Round-Robin - Live Scheduling 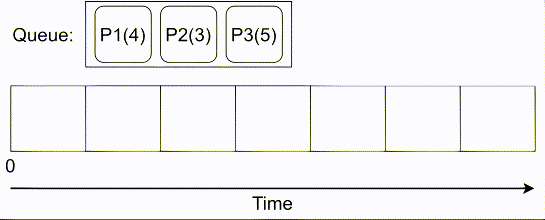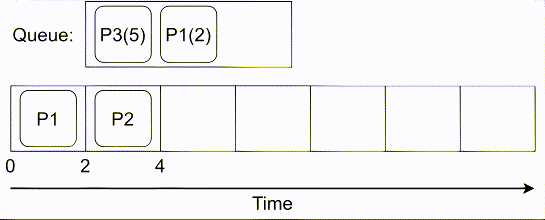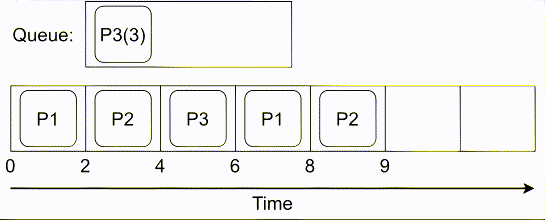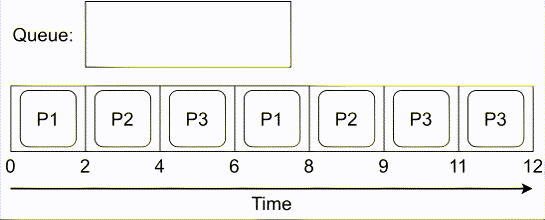 ---- #### Round-Robin - Analysis * Large time slice: * high throughput (fewer context switches) * low fairness (threads at the back of the queue spend more time in READY) * Small time slice: * low throughput * high fairness --- ### Round-Robin - Real Life (Unikraft) * [Cooperative scheduler](https://github.com/unikraft/unikraft/blob/staging/lib/ukschedcoop/schedcoop.c) * Lists used as queues for READY and WAITING processes: ```c struct schedcoop_private { struct uk_thread_list thread_list; struct uk_thread_list sleeping_threads; }; ``` * `yield` means scheduling another thread: ```c static void schedcoop_yield(struct uk_sched *s) { schedcoop_schedule(s); } ``` ---- #### Cooperative Scheduler - Demo * First, run `./do.sh setup && ./do.sh build` * Without calling `uk_sched_yield`, Thread 1 runs until finished: ```console [1 - 12 | 14 - 25] student@os:~/.../demo/cooperative-scheduling$ ./do.sh run_nocoop [...] Thread 1 created! Thread 1: step 0 Thread 1: step 1 Thread 1: step 2 Thread 1 finished! Thread 2 created! Thread 2: step 0 Thread 2: step 1 Thread 2: step 2 Thread 2 finished! student@os:~/.../demo/cooperative-scheduling$ ./do.sh run_coop [...] Thread 1 created! Thread 1: step 0 Thread 2 created! Thread 2: step 0 Thread 1: step 1 Thread 2: step 1 Thread 1: step 2 Thread 2: step 2 Thread 1 finished! Thread 2 finished! ``` --- ### Completely Fair Scheduler (CFS) * Schedule the thread that has run **the least amount of time (vruntime)** * Store READY threads in a **Red-Black Tree**, sorted by **vruntime** * Use time slices, like Round-Robin * During a context switch: * If the currently RUNNING task is over, terminate it * Otherwise, increase its vruntime and add it to RBTree * Move the **leftmost** thread in RBTree to RUNNING ---- #### CFS - Analysis * Context switch complexity: * Add thread to RBTree: `O(log(num_threads))` * Extract leftmost thread in the RBTree: `O(1)` (keep a pointer to it) * Overall complexity: `O(log(num_threads))` * Time slice size: same tradeoff as Round-Robin --- ### Fixed Priority Scheduling * Each thread has a priority * Threads with higher priority run more often * Threads with lower priority are starved * Easier to implement ---- #### Fixed Priority Scheduling - `nice` * Lower `nice`-ness = higher priority * Values in `[-20, 19]` ```console [1 - 2 | 3 - 8 | 9 - 10 | 11 - 12] student@os:~$ nice -10 bash & [1] 5753 student@os:~$ ps -e -o pid,ni,comm PID NI COMMAND 1 0 init [...] 5753 10 bash 5752 0 ps student@os:~$ sudo renice -n -20 -p 5753 5753 (process ID) old priority 10, new priority -20 student@os:~$ ps -e -o pid,ni,comm | grep 5753 5753 -20 bash ``` ---- #### Priority-Based Round-Robin * The scheduler keeps a list of queues, one for each priority * During a context switch, the new RUNNING thread is chosen from the highest priority non-empty queue  --- ### Dynamic-Priority Scheduling * Problems with static priorities: * Low-priority threads are starved * Unfair for I/O bound threads * Solution: * Decrease priority of RUNNING threads * Increase priority of WAITING threads --- ## Synchronization --- #### Synchronization - Why? * Each thread believes it's the only one running * ... but this is not true * Threads share resources: * RAM * files * networking * CPU ---- #### Synchronization - How? * We want to give a thread **exclusive access** to a resource at a given time * Other threads **wait** to receive access ---- #### Synchronization - Example * `demo/race-condition/race_condition.c` * `var++` equivalency (**critical section**): 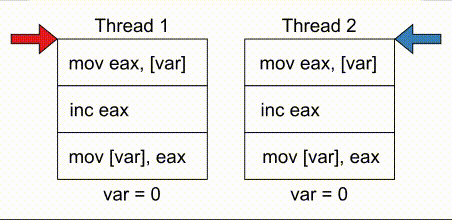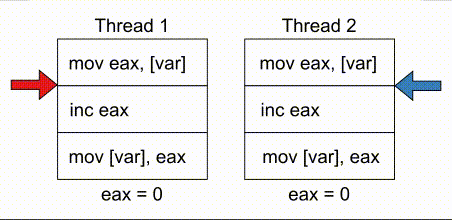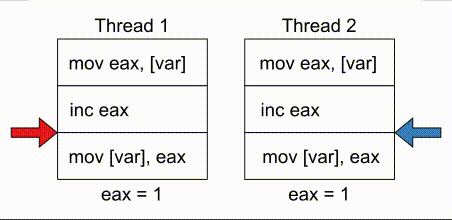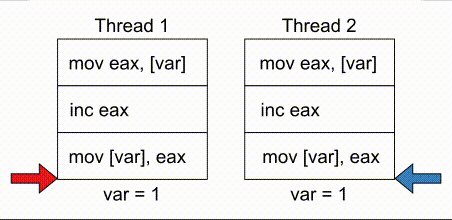 * In the end `var = 1` or `var = 2` ---- #### Synchronization Mistake - TOCTOU ```c if (lock = 0) { lock = 1; /* critical section */ lock = 0; } ``` 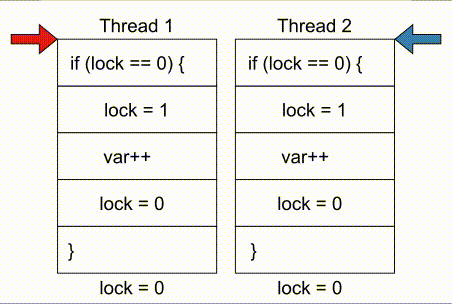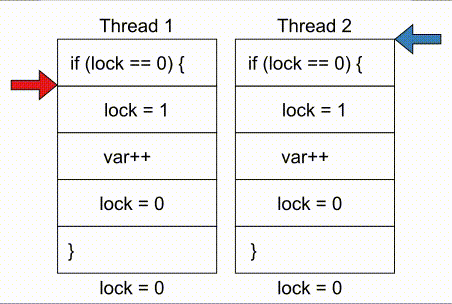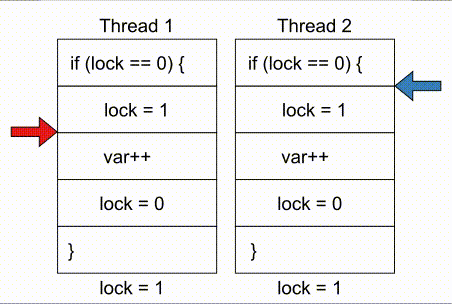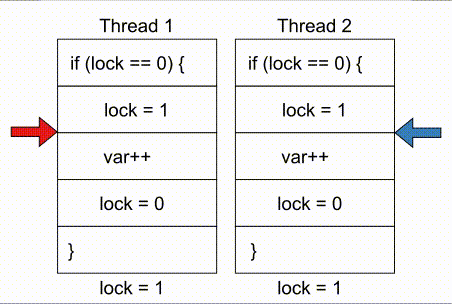 * **Wrong:** threads enter critical section simultaneously ---- #### Synchronization - Solution * Only allow **one thread** to access the critical section at a given time (mutual exclusion) 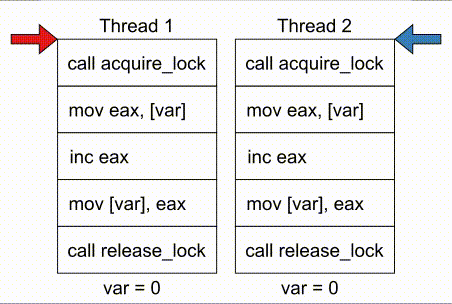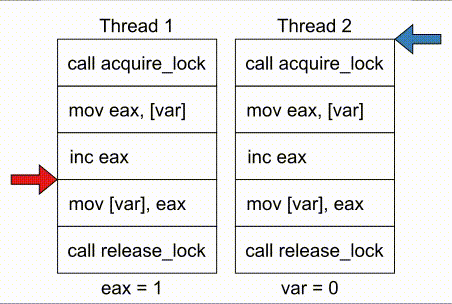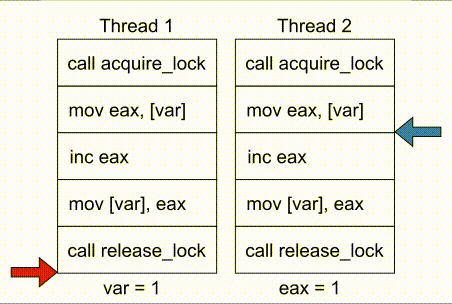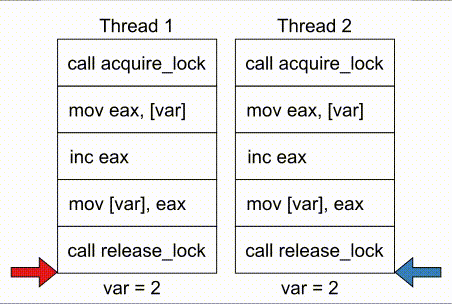 * In the end `var` is **always** 2 * [Quiz](../quiz/not-race-condition.md) --- ## Mutual Exclusion --- ### Mutual Exclusion - Atomicity * Access to a resource is restricted to a single thread * Use **atomic** instructions provided by the ISA: (on x86: the `lock` prefix) * Eg: `lock inc dword [var]` * The CPU core has exclusive access to the cache and data bus while executing the instruction * Use architecture-independent wrappers: * [GCC built-ins](https://gcc.gnu.org/onlinedocs/gcc/_005f_005fatomic-Builtins.html) (eg. `__atomic_add_fetch`) * libc functions from [`stdatomic.h`](https://en.cppreference.com/w/c/atomic) (eg. `atomic_flag_test_and_set`) ---- #### Atomicity in Action * `demo/race-condition/race_condition_atomic_assembly.c` * "inline assembly version" of `__atomic_add_fetch` * similar running times ---- #### Mutual Exclusion - Spinlock * Makes critical section **atomic** * `lock` with **busy-waiting** - loop until you gain access (`lock == 1`): ```c void spin_lock() { while (atomic_flag_test_and_set(&lock)) ; } ``` * `unlock` - simple assignment. * The result is the same even with race conditions ```c void spin_unlock() { lock = 0; } ``` ---- #### Spinlock - Analysis * Advantages: * Simple to implement * Fast when lock is (almost) immediately acquired * Disadvantage: * Overhead: runs on the CPU while waiting for the lock (doing nothing) --- ### Mutual Exclusion - Mutex ```c [1 - 3 | 5 - 9 | 12 - 19 | 21 - 26] struct mutex { /* Use internal lock for `atomic_flag_test_and_set`. */ int lock; /** * Store WAITING threads in this queue. Move one thread to READY when * another one calls `mutex_unlock`. */ struct queue *queue; }; void mutex_lock(struct mutex *m) { while (atomic_flag_test_and_set(&m->lock)) { thread = current_thread(); queue_push(m->queue, thread); move_to_waiting(thread); } } void mutex_unlock(struct mutex *m) { m->lock = 0; thread = queue_pop(m->queue); move_to_ready(thread); } ``` ---- #### Mutex - Analysis * Prevents overhead from busy-waiting * Threads move to WAITING state while waiting for the lock * Introduces overhead from context switch * Releasing a mutex held by another thread is [**undefinded behaviour**](https://pubs.opengroup.org/onlinepubs/9699919799/functions/pthread_mutex_lock.html) ---- #### Who Should Release the Lock?  --- ### Mutual Exclusion - Overhead * The more complex the synchronization mechanism, the higher the overhead: ```console [1 - 2 | 3 - 4 | 5 - 6 | 7 - 8] student@os:~/.../compute/lecture/demo/race-condition$ ./race_condition var = 1232611; time = 14 ms student@os:~/.../compute/lecture/demo/race-condition$ ./race_condition_atomic var = 2000000; time = 31 ms student@os:~/.../compute/lecture/demo/race-condition$ ./race_condition_spinlock var = 2000000; time = 73 ms student@os:~/.../compute/lecture/demo/race-condition$ ./race_condition_mutex var = 2000000; time = 98 ms ``` * Why is the spinlock faster? * **Short** critical section, so the lock is acquired fast * The context switches performed by the mutex are costlier ---- #### Spinlock vs Mutex | Spinlock | Mutex | | :--------------------------------------- | :--------------------------------------- | | Busy waiting | Yields CPU | | Good for short critical sections | Good for complex critical sections | | Only 1 thread can enter critical section | Only 1 thread can enter critical section | ---- ### Critical Section - Granularity * What if we place all the code in `increase_var` in a critical section? * Short critical sections mean more frequent context switches * Large critical sections mean less parallelism (code runs almost sequentially) ```console student@os:~/.../compute/lecture/demo/granularity$ ./coarse_granularity var = 2000000; time = 36 ms student@os:~/.../compute/lecture/demo/granularity$ ./fine_granularity var = 2000000; time = 1268 ms ``` --- ### Deadlock * Circular dependency * Threads cyclically wait for each other  ```console student@os:~/.../compute/lecture/demo/deadlock$ python3 deadlock.py Thread 1: locked resource 1. Waiting for resource 2... Thread 2: locked resource 2. Waiting for resource 1... ``` --- ## Notifications --- ### Locks vs Notifications  ---- #### Locks vs Notifications * Locks: * isolate **critical sections** * thread that calls `unlock()` must hold the lock * Notifications (conditions and semaphores): * one thread waits for an **event** * **another thread** notifies waiting thread on event completion ---- #### Two Types of Primitives 1. For mutual exclusion: * mutexes, spinlocks * methods: `lock()` and `unlock()` 1. For ordering: * semaphore, condition variables * methdos: `wait()` and `notify()` --- ### Semaphores * Atomic counter * Counter can take values greater than 1 * `acquire() ~ counter--`: * Returns if `counter > 0` * Thread blocks if `counter == 0` * `release() ~ counter++`: * Signals waiting threads --- ### Condition Variables * More complex synchronization logic * Similar to but more flexible than semaphores * A thread is suspended until a condition (logical predicate) is met * Always used with mutexes (evaluating the condition is **not atomic**) ---- #### Condition Variables - API * `wait`: suspend the thread until the condition is met * need to acquire the lock before waiting * this is needed to check the condition in a thread-safe manner * `wait` releases the lock ```python cond.acquire() cond.wait() ``` * `notify`: wake up **one** thread waiting on the condition * `notify_all`: wake up **all** threads waiting on the condition * If no thread is woken up (because none is waiting), the notification has no effect! ---- #### Condition Variables - Demo ```console student@os:~/.../compute/lecture/demo/condition$ python3 condition.py Waiting thread: waiting for main thread... Main thread: type "notify" to notify waiting thread waiting thread is sleeping until woken up by main thread notify Waiting thread: notified by main thread ``` --- ## Barrier --- ### Barrier * The code before the barrier is executed by **all threads** before the code after the barrier * Threads move to WAITING upon reaching the barrier * Threads move back to READY when the last thread reaches the barrier ---- #### Barrier - Demo ```console [1 - 7 | 9 - 16] student@os:~/.../compute/lecture/demo/barrier$ python3 barrier.py Before barrier: thread name = thread-0 After barrier: thread name = thread-0 Before barrier: thread name = thread-2 After barrier: thread name = thread-2 Before barrier: thread name = thread-1 After barrier: thread name = thread-1 student@os:~/.../compute/lecture/demo/barrier$ python3 barrier.py --use-barrier Before barrier: thread name = thread-0 Before barrier: thread name = thread-1 Before barrier: thread name = thread-2 After barrier: thread name = thread-2 After barrier: thread name = thread-0 After barrier: thread name = thread-1 ``` * Notice that threads reach the barrier and end in arbitrary order --- ## Thread-safety and Reentrancy --- ### Thread-safety and Reentrancy * **Thread-safe function:** called simultaneously from multiple threads without race conditions * **Reentrant function:** preempted at any time and re-called from the same thread with the same effects * Different from recursion:  ---- #### Thread-safety and Reentrancy - Examples ```c [1 - 8 | 10 - 16 | 18 - 24 | 26 - 30] /* Not thread-safe, not reentrant: */ int tmp int add2(int x) { tmp = x; /* Preempt here */ return tmp + 2; } /* Reentrant, not thread-safe: */ int tmp int add2(int x) { tmp = x; return x + 2; } /* Thread-safe not reentrant: */ thread_local int tmp int add2(int x) { tmp = x; return tmp + 2; } /* Both thread-safe and reentrant: */ int add2(int x) { return x + 2; } ``` --- ## Cool Extra Stuff --- ### Recap - `exec()` * Replaces the VAS of a process with that of another one * Path to the binary file from which to start the second process given as argument * The file descriptors of the original process are maintained * Only returns in case of error * Otherwise, the new process takes over ---- #### Create a new process - `fork()` + `exec()` * [Quiz](../quiz/exec-without-fork.md) * "Save" the shell before calling `exec("/bin/ls")` * Use `fork()` and only the child calls `exec()`  ---- #### Linux Syscalls ```console student@os:~/.../compute/lecture/demo/create-process$ strace ./fork_exec [...] clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f7e83aa4810) = 5279 [...] ``` * `fork()` and `pthread_create()` are `libc` wrappers to the same syscall: `clone()` --- ### Libc vs Linux vs Windows * Libc approach - `system`: ```console [1 | 2 | 3 | 5 | 7 | 9] student@os:~/.../compute/lecture/demo/create-process$ strace -ff -e clone,execve ./system execve("./system", ["./system"], 0x7ffff3f20008 /* 60 vars */) = 0 clone(child_stack=0x7f3fa624aff0, flags=CLONE_VM|CLONE_VFORK|SIGCHLDstrace: Process 117770 attached <unfinished ...> [pid 117770] execve("/bin/sh", ["sh", "-c", "ls -la"], 0x7ffdac7acfe8 /* 60 vars */ [...] [pid 117770] clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f9292b28850) = 117771 strace: Process 117771 attached [pid 117771] execve("/usr/bin/ls", ["ls", "-la"], 0x55c700084048 /* 60 vars */) = 0 [...] ``` ---- #### Libc vs Linux vs Windows * `system` first creates a new shell (`execve("/bin/sh"`) * This shell now spawns `ls -la` (`execve("/usr/bin/ls", ["ls", "-la"]`) ---- #### Libc vs Linux vs Windows * Linux approach - `posix_spawn()` and `fork()` + `exec()`: ```console [1 | 2 | 3 | 5 | 7 | 8 | 9 | 11 | 13] student@os:~/.../compute/lecture/demo/create-process$ strace -ff -e clone,execve ./posix_spawn execve("./posix_spawn", ["./posix_spawn"], 0x7ffcfed53928 /* 60 vars */) = 0 clone(child_stack=0x7f842691eff0, flags=CLONE_VM|CLONE_VFORK|SIGCHLDstrace: Process 118949 attached <unfinished ...> [pid 118949] execve("/bin/ls", ["-la"], 0x7ffc97832878 /* 60 vars */ <unfinished ...> student@os:~/.../compute/lecture/demo/create-process$ strace -ff -e clone,execve ./fork_exec execve("./fork_exec", ["./fork_exec"], 0x7ffdb2c85028 /* 60 vars */) = 0 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 119051 attached [...] [pid 119051] execve("/home/student/.local/bin/ls", ["-la"], 0x7ffee90fee78 /* 60 vars */) = -1 [...] [pid 119051] execve("/usr/bin/ls", ["-la"], 0x7ffee90fee78 /* 60 vars */) = 0 ``` * The "manual" method (`fork()` + `exec()`) tries all `$PATH` entries before finding `"/usr/bin/ls"` ---- #### Libc vs Linux vs Windows * Windows approach: `CreateProcess` ```console PS C:\...\lecture\demo\create-process> .\create_process.exe [parent] PID = 11876; child PID = 10376; Waiting... [...] ``` * The command given to `CreateProcess` must specify the interpreter: `cmd` --- ### `fork()` vs `pthread_create()` ```console [1 - 2 | 3 - 4] student@os:~/.../compute/lecture/demo/create-process$ strace -e clone ./fork_exec clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f7e83aa4810) = 5302 student@os:~/.../compute/lecture/demo/create-thread$ strace -e clone ./create_thread clone(child_stack=0x7f9ea7df0fb0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, tls=0x7f9ea7df1700, child_tidptr=0x7f9ea7df19d0) = 5389 ``` * From the flags, the parent and the child **thread** share: * `CLONE_VM`: VAS (no copy-on-write) * `CLONE_FS`: FS information (root, umask, cwd) * `CLONE_FILES`: File descriptor table * `CLONE_SIGHAND`: Signal handlers --- ### The Suspended States  ---- #### The Suspended States * **SUSPENDED READY / WAITING:** placed on secondary storage (**swap area**) due to lack of RAM * Brought back to READY / WAITING when more RAM is available * Threads can move from SUSPENDED WAITING to SUSPENDED READY when I/O completes * Impossible to move from SUSPENDED READY to SUSPENDED WAITING (threads cannot perform I/O calls without running) --- ### Kernel Level Threads * Advantages: * blocking actions only stall current thread * hardware (SMP) support * Disadvantages: * slow context switch * difficult to implement and maintain * kernel space scheduler (more complex) * Partial solution: **user level threads** ---- #### Thread Implementations | User level | Kernel level | | :------------------------------: | :----------------------------------------: | | implemented by libraries | implemented by the kernel | | blocking actions stall process | blocking actions only stall current thread | | more mapped on one kernel thread | provide support for user level threads | | Java, Python | Linux KThreads, Windows threads |